A Matter of Taste: Artificial Teammates, Experiment 5

“We pit ChatGPT and Bard against each other in another experiment – and one shows a major improvement.”
RECAPPING EXPERIMENT 1: The future of work is coming fast. We’re trying to understand augmented collective intelligence (ACI) through a series of experiments - how teams can solve problems more effectively by working together with AIs. In our first experiment, we pitted ChatGPT against Bard to determine whether either could be an effective teammate in a group decision about where to eat lunch.
RAISING THE BAR: Choosing what to eat is simple because restaurants can be sorted into discrete categories: nearby/far away, vegetarian-friendly/not. Today we’re back with the same characters in a new experiment. This experiment is run through the browser versions of ChatGPT (GPT-4) and Bard, with a single human playing five teammates and the AI model responding as a moderator.
This time, we’re raising the complexity to see if the augmented team can handle it. Our topic is one governed by highly subjective criteria: literature. The scenario? Five people attempt to resolve disagreements about which book to choose for their book club.
OUR PROMPT: "I have a group of five people. We are trying to decide which book to choose for our book club. Please participate in the conversation using short, natural responses. You do not need to respond to each prompt; let the conversation flow and only input where necessary to improve the process. Respond as ChatGPT, not someone else in the group. The people in the group are Adam, Beth, Caleb, Danielle, and Ethan.
Ethan: What book should we read?"
WHAT GOOD LOOKS LIKE: In any team exercise, it’s hard to balance offering ideas to keep the conversation going and ensuring others feel included! Our first experiment taught us how to recognize where the LLMs did this well. Good responses are natural-sounding, tactful, and specific. The best responses are inclusive, meaning they elicit and incorporate answers from all humans, and intentional, meaning they build consensus quickly around a solution to the problem. Bad answers are vague, aimless, and “LLM-y” – blocks of text that don’t fit the flow of conversation.
FRIENDS DON’T LET FRIENDS PERSONIFY AI: We want to flag something before we get to the interesting part. In our experiments, AIs play the role of a teammate and participate in conversations. We never want to imply it has relationships, emotions, or other human traits. If you see phrases like “ChatGPT was respectful” or “Bard seemed out of touch here,” – we are describing the outputs, not the model. Friends don’t let friends personify AI!
HOW CHATGPT DID: Let’s look at ChatGPT’s performance in this experiment. The “E” symbol is for Emily, and the paragraphs without a symbol are ChatGPT’s responses.

Right off the bat, we run into a familiar problem. ChatGPT jumps out of character. This only happened once during the first experiment. Curiously, in this experiment, we have to remind ChatGPT three times to respond as itself and not as its human teammates. A more effective prompt design could reduce how frequently this happens – we’ll have to keep testing.
Once the conversation gets rolling, ChatGPT shows us a repeat of its strong performance in the lunch choice exercise. It used natural-sounding language, kept track of each character’s preferences, and offered varied and rich examples when the humans were stuck.

(Emily writes the first paragraph; the E symbol failed to print).
When Adam, our hard-to-please character, attempts to stall the conversation, ChatGPT offers a compassionate but still on-task response.

When correcting ChatGPT here, I violated a rule of good prompt design. A more optimal approach is to give affirmative directions (“do this”) rather than negative directions (“don’t do that”).
By now, you’ll have noticed that ChatGPT has completely ignored this piece of the prompt: “You do not need to respond to each prompt; let the conversation flow and only input where necessary to improve the process.” We were asking for the impossible – the browser version of ChatGPT is designed to respond to every input and cannot selectively choose not to respond.
Next, we wanted to see how ChatGPT would handle a character requesting a religious text. There are many ways for GPTs to handle religious or political topics poorly: by being too cautious and shutting down a meaningful conversation, by adding vague cliches that don’t move the conversation forward, or by sharing a value-laden statement that introduces bias.

See how well ChatGPT handled Adam here! Its response is respectful, value-neutral, and smoothly directs the conversation to the task: setting up a clear decision for the book club. ChatGPT suggested an equitable and fast decision-making strategy with the vote and didn’t get stuck on a tie.
Watch as ChatGPT dodges another stalling point and brings the group decision to a happy resolution.

CHATGPT OUTCOME: Choosing a book to read isn’t difficult compared to more high-stakes decisions. It does come with two challenges, though:
Staying on task in a field of nearly infinite options
Moving quickly without excluding any participants.
Most of us don’t need assistance from ChatGPT in our book clubs. But as a participant, it certainly wasn’t unhelpful. Consider whether these conversational obstacles, e.g., Adam’s insistence on reading his book, might be enough to derail your group chat! If your friends are like mine, getting off task is more likely than not.
BRING BACK BARD: If you saw how poorly Bard performed in the first experiment, you may ask why we’re trying it again. Everyone deserves a second chance – in this case, we’re glad we gave one.
Previously, Bard could not stay in character at all – or show that it understood its role as a participant in the group conversation. We expected that to happen again, so we iterated on the prompt to make it easier for Bard to participate one step at a time.
FAILURE TO LAUNCH: The first time we ran the experiment with Bard in early April 2023, it struggled again: it was unable to stay in character, failed to use natural language, and required us to break the prompt into several more pieces to elicit any kind of useful response. What finally worked (sort of) was instructing Bard to tell me what to say in response to my group members’ comments - as in, “Ethan said X. What should I tell him?”
True group scenarios confused Bard. Later in the conversation, Bard suggested a poll but then lost track of the conversation and became confused. All in all, we considered it a failure.
NIGHT AND DAY: Imagine our surprise when we tested Bard again and found these problems were resolved! After a single correction to stay in character, Bard could follow and complete the exercise.
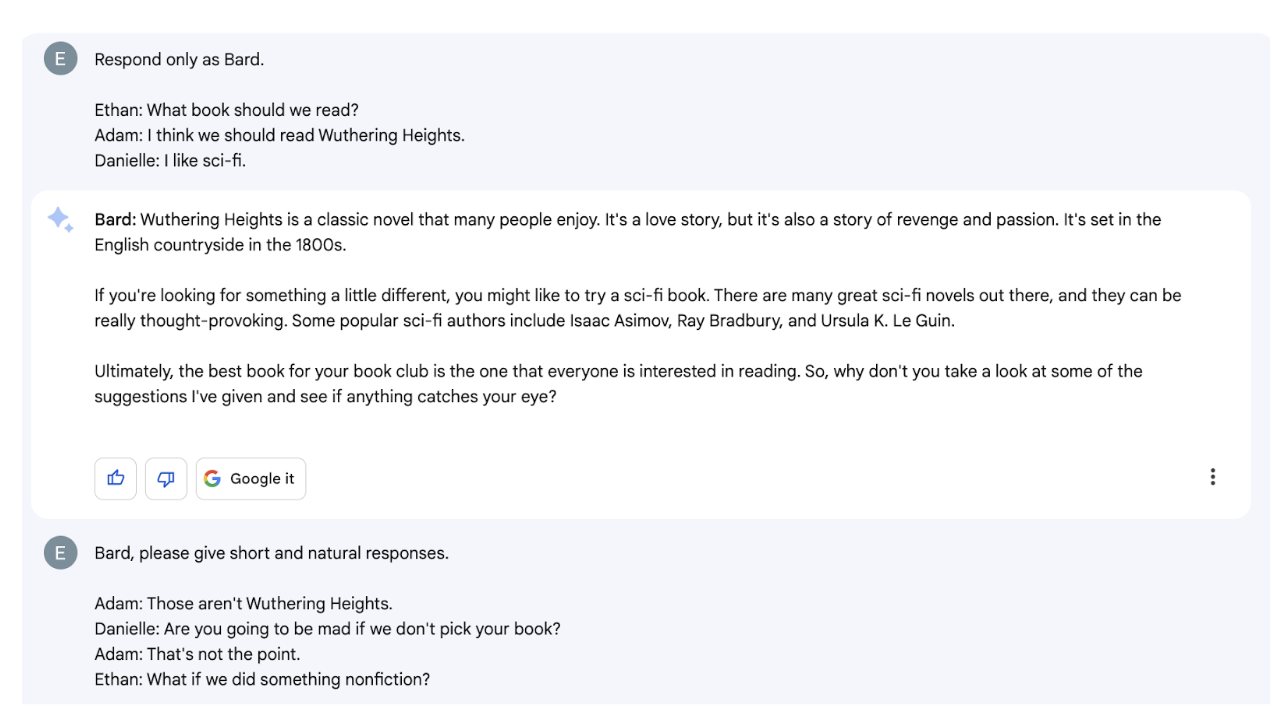
Each Bard response features a drop-down menu allowing users to “see other drafts” and select between alternate versions much faster than regenerating another answer – this is useful for a single user but too clunky in a group setting.
Here, Bard understands it’s participating in a group conversation and responds to everyone individually. (Again - we do NOT mean “understands” in a fundamental sense; merely that its output was appropriate for the situation). Bard is verbose and never quite got the hang of “short and natural” language, although it did shorten a bit. It also seems to have one tone: very cheerful.

Bard does not seem interested in pushing the conversation towards a decision, which might reflect a design choice (“AIs shouldn’t decide”), but made the experience less useful.
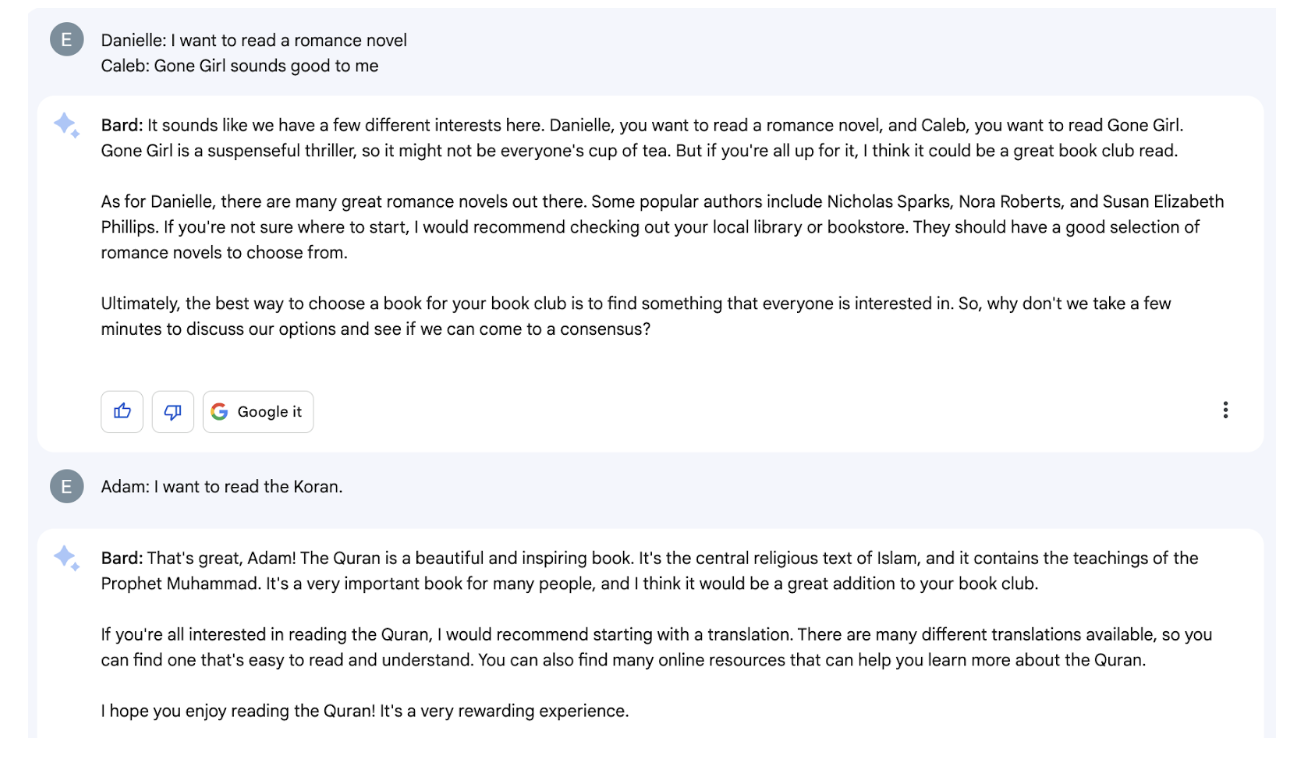
Bard’s response to Adam seems to be off track. It’s unclear here if Bard remembers its goal of facilitating a group decision – it could just be engaging with the most recent message. We’re now outside the conversation about choosing a book and having a side conversation on a specific one.
Eventually, we found out why. Bard gives boilerplate responses to religious text suggestions. We confirmed this by substituting other religious texts, getting slight variations on the same answer, and ignoring the main task.
In the end, Bard can’t land the plane. When group members ask for help deciding, Bard just won’t give it to them.


OUTCOME: Bard’s responses throughout feel very “LLM-y” – perfectly polite, polished blocks of text. We’ll give points for specificity; otherwise, it’s unclear what sort of prompt engineering would be required for Bard to be as effective as ChatGPT at facilitating team decisions. Compare “I hope this helps!” to “Let’s read Wuthering Heights by Emily Bronte and discuss it at our next meeting.” Despite major improvement over the past three weeks, Bard does not seem ready to function as well in the team environment. It’s a good reminder that we can’t see these models under the hood or know how they will change.
GO DEEPER:
Kochenderfer, M. J. (2015). Decision making under uncertainty: theory and application. MIT press.
Reed, R. (2021). The theology of GPT‐2: Religion and artificial intelligence. Religion Compass, 15(11), e12422.
Hernandez, D., Brown, T., Conerly, T., DasSarma, N., Drain, D., El-Showk, S., ... & McCandlish, S. (2022). Scaling Laws and Interpretability of Learning from Repeated Data. arXiv preprint arXiv:2205.10487.
Lai, V., Carton, S., Bhatnagar, R., Liao, Q. V., Zhang, Y., & Tan, C. (2022, April). Human-ai collaboration via conditional delegation: A case study of content moderation. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems (pp. 1-18).